In vielen Datenbanken sammeln sich mit der Zeit redundante Informationen. Das führt zu folgenden Problemen:
- Redundanz: Mehrfache Speicherung derselben Information.
- Anomalien: Probleme beim Einfügen, Aktualisieren oder Löschen von Daten.
- Inkonsistenzen: Unterschiedliche Werte für dieselben Informationen in verschiedenen Tabellen.
Stell dir vor, ein Online-Shop speichert Kundenadressen in fünf verschiedenen Tabellen. Ändert ein Kunde seine Adresse, muss diese an mehreren Stellen aktualisiert werden. Bei diesem Szenario kann sich jeder vorstellen, wie schnell es passiert ist, dass an unterschiedlichen Stellen verschiedene Adressen vorliegen.
1970 legte Edgar F. Codd die Grundlagen für relationale Datenbanken und die Normalisierung. Sein Ziel war es, Daten konsistent, redundantfrei und effizient speicherbar zu machen.
Ziel der Normalisierung
Normalisierung dient dazu, Datenbanken aufzuräumen und zu strukturieren. Die Hauptziele sind:
- Datenintegrität: Korrekte und konsistente Daten
- Redundanzfreiheit: Jede Information wird nur einmal gespeichert
- Anomalie-Vermeidung: Probleme beim Einfügen, Aktualisieren oder Löschen werden reduziert
- Skalierbarkeit: Datenbanken lassen sich leichter erweitern und warten
Praktisch bedeutet das: Daten werden so organisiert, dass sie leichter wartbar, fehlerfrei und performant sind.

Theoretische Fundamente
Funktionale Abhängigkeiten
Funktionale Abhängigkeiten bilden die Grundlage der Normalisierung. Sie zeigen, wie ein Attribut oder eine Attributgruppe andere Attribute eindeutig bestimmt.
- Notation: X → Y bedeutet: Die Attributmenge X bestimmt eindeutig Y.
- Beispiel: postleitzahl → stadt – jede Postleitzahl gehört eindeutig zu einer Stadt.
Wenn eine funktionale Abhängigkeit verletzt wird, entstehen Redundanzen oder Inkonsistenzen in der Datenbank.
Schlüsselkonzepte
Wichtige Begriffe, die du verstehen solltest:
- Superkey: Eine Attributmenge, die jeden Datensatz eindeutig identifiziert. Beispiel: Kombination aus kunden_id und email.
- Kandidatenschlüssel: Minimaler Superkey, bei dem kein Attribut überflüssig ist. Beispiel: Nur kunden_id, wenn sie allein ausreicht.
- Primärschlüssel: Ein gewählter Kandidatenschlüssel, der zur eindeutigen Identifikation von Datensätzen verwendet wird.
Transitive Abhängigkeiten
Eine transitive Abhängigkeit liegt vor, wenn ein Attribut indirekt über ein anderes bestimmt wird. Beispiel:
- mitarbeiter_id → abteilung_id → abteilungs_budget
- Hier hängt abteilungs_budget nicht direkt von mitarbeiter_id ab, sondern nur über abteilung_id. Solche Abhängigkeiten verhindern eine saubere Datenstruktur und müssen erkannt werden, um die dritte Normalform (3NF) korrekt anzuwenden.
Durch das Verständnis dieser Grundlagen kannst du später die verschiedenen Normalformen Schritt für Schritt anwenden und die Datenbank optimal strukturieren.


Die Normalformen im Detail
Erste Normalform (1NF)
Die erste Normalform sorgt dafür, dass alle Attribute einer Tabelle atomar sind – das heißt, jedes Feld enthält genau einen Wert, nicht mehrere Informationen zusammen.Beispiel für eine Verletzung der 1NF:
-- Nicht-1NF: Mehrfachwerte in einer Zelle
CREATE TABLE bestellungen (
id INT PRIMARY KEY,
produkte VARCHAR(255) -- 'ProduktA, ProduktB, ...'
);| id | produkte |
|---|---|
| 1 | ProduktA, ProduktB |
| 2 | ProduktC |
Lösung: Atomare Werte
Teile die Produkte in separate Zeilen auf:CREATE TABLE bestellpositionen (
bestell_id INT,
produkt_name VARCHAR(50)
);| bestell_id | produkt_name |
|---|---|
| 1 | ProduktA |
| 1 | ProduktB |
| 2 | ProduktC |
Zweite Normalform (2NF)
Die zweite Normalform entfernt Teilabhängigkeiten. Jedes Nicht-Schlüssel-Attribut muss vom gesamten Primärschlüssel abhängen.Beispiel für eine 2NF-Verletzung:
CREATE TABLE bestellpositionen (
bestell_id INT,
artikel_id INT,
artikel_name VARCHAR(50), -- Problem!
PRIMARY KEY (bestell_id, artikel_id)
);| bestell_id | artikel_id | artikel_name |
|---|---|---|
| 1 | 101 | Schraube |
| 1 | 102 | Hammer |
Lösung: Zerlegung in zwei Tabellen
CREATE TABLE artikel (
artikel_id INT PRIMARY KEY,
artikel_name VARCHAR(50)
);
CREATE TABLE bestellpositionen (
bestell_id INT,
artikel_id INT,
PRIMARY KEY (bestell_id, artikel_id)
);| artikel_id | artikel_name |
|---|---|
| 101 | Schraube |
| 102 | Hammer |
| bestell_id | artikel_id |
|---|---|
| 1 | 101 |
| 1 | 102 |
Dritte Normalform (3NF)
Die dritte Normalform entfernt transitive Abhängigkeiten. Ein Nicht-Schlüssel-Attribut darf nicht von einem anderen Nicht-Schlüssel-Attribut abhängen.Beispiel:
mitarbeiter_id → abteilung_id → abteilungs_budget| mitarbeiter_id | name | abteilung_id | abteilungs_budget |
|---|---|---|---|
| 1 | Anna | 10 | 5000 |
| 2 | Ben | 20 | 8000 |
Lösung: Zerlegung in zwei Tabellen
CREATE TABLE mitarbeiter (
mitarbeiter_id INT PRIMARY KEY,
name VARCHAR(50),
abteilung_id INT
);
CREATE TABLE abteilungen (
abteilung_id INT PRIMARY KEY,
abteilungs_budget DECIMAL(10,2)
);| mitarbeiter_id | name | abteilung_id |
|---|---|---|
| 1 | Anna | 10 |
| 2 | Ben | 20 |
| abteilung_id | abteilungs_budget |
|---|---|
| 10 | 5000 |
| 20 | 8000 |
Praxis: Normalisierung Schritt für Schritt
Stell dir vor, du hast eine Fahrzeugvermietung mit einer Tabelle, die zu viele Informationen enthält – ein klassischer Kandidat für Normalisierung. Die Ausgangstabelle hat 20 Attribute, hier ein vereinfachtes Beispiel:
| miet_id | kunde_name | kunde_adresse | fahrzeug_id | fahrzeug_typ | preis |
|---|---|---|---|---|---|
| 1 | Anna Müller | Musterstraße 1, Berlin | 101 | PKW | 50 |
| 2 | Ben Schmidt | Beispielweg 5, Hamburg | 102 | Transporter | 80 |
| 3 | Anna Müller | Musterstraße 1, Berlin | 103 | PKW | 50 |
Schritt 1: Funktionale Abhängigkeiten identifizieren
Überlege, welche Attribute voneinander abhängen:
- fahrzeug_id → fahrzeug_typ
- kunde_name → kunde_adresse
- miet_id → fahrzeug_id, kunde_name, preis
Schritt 2: Kandidatenschlüssel bestimmen
In dieser Tabelle könnte miet_id als Primärschlüssel dienen, da jede Miete eindeutig ist.
Schritt 3: Erste Normalform (1NF)
Stelle sicher, dass jede Zelle nur einen Wert enthält. In unserem Beispiel ist die Tabelle bereits atomar – 1NF ist erfüllt.
Schritt 4: Zweite Normalform (2NF)
Entferne Teilabhängigkeiten, indem du die Daten in mehrere Tabellen aufteilst:
CREATE TABLE kunden (
kunde_id INT PRIMARY KEY,
kunde_name VARCHAR(50),
kunde_adresse VARCHAR(100)
);
CREATE TABLE fahrzeuge (
fahrzeug_id INT PRIMARY KEY,
fahrzeug_typ VARCHAR(50)
);
CREATE TABLE mietungen (
miet_id INT PRIMARY KEY,
kunde_id INT,
fahrzeug_id INT,
preis DECIMAL(10,2)
);Daten nach Zerlegung:
Kunden:
| kunde_id | kunde_name | kunde_adresse |
|---|---|---|
| 1 | Anna Müller | Musterstraße 1, Berlin |
| 2 | Ben Schmidt | Beispielweg 5, Hamburg |
Fahrzeuge:
| fahrzeug_id | fahrzeug_typ |
|---|---|
| 101 | PKW |
| 102 | Transporter |
| 103 | PKW |
Mietungen:
| miet_id | kunde_id | fahrzeug_id | preis |
|---|---|---|---|
| 1 | 1 | 101 | 50 |
| 2 | 2 | 102 | 80 |
| 3 | 1 | 103 | 50 |
Schritt 5: Dritte Normalform (3NF)
Überprüfe, ob transitive Abhängigkeiten existieren. In unserem Beispiel sind alle Nicht-Schlüssel-Attribute direkt vom Primärschlüssel abhängig. Damit ist die 3NF erfüllt.
Schritt 6: Optional: Boyce-Codd-Normalform (BCNF)
Falls es noch spezielle Überlappungen bei Schlüsseln gäbe, könnte man weiter zerlegen, um jede Determinante zum Kandidatenschlüssel zu machen.
Mit dieser Schritt-für-Schritt-Methode wird deutlich, wie man aus einer großen, unübersichtlichen Tabelle sauber normalisierte Tabellen erstellt – Datenredundanz und Anomalien werden vermieden.
Denormalisierung: Wann Regeln gebrochen werden dürfen
Normalisierung ist super für Datenintegrität, kann aber bei großen Systemen manchmal die Performance bremsen. Denormalisierung bedeutet, bewusst Informationen zusammenzuführen, um Abfragen schneller zu machen – mit kalkuliertem Risiko.
Performance vs. Integrität
| Szenario | Normalisiert | Denormalisiert |
|---|---|---|
| OLTP-Systeme (z. B. Buchungssystem) | ✓ Ideal | ✗ Risiko für Anomalien |
| Data Warehousing (Analysen, Reports) | ✗ Langsam | ✓ Empfohlen für schnelle Abfragen |
Techniken der Denormalisierung
- Materialized Views (z. B. in PostgreSQL): Vorberechnete Tabellen, die komplexe Joins speichern.
- Berechnete Spalten (z. B. in SQL Server): Werte werden einmal berechnet und gespeichert, statt jedes Mal neu zu berechnen.
Beispiel: Mietungen denormalisiert
Aus der vorherigen Normalisierung hatten wir drei Tabellen: kunden, fahrzeuge und mietungen. Denormalisiert könnten wir alles in einer Tabelle speichern, um Abfragen schneller zu machen:
| miet_id | kunde_name | kunde_adresse | fahrzeug_typ | preis |
|---|---|---|---|---|
| 1 | Anna Müller | Musterstraße 1, Berlin | PKW | 50 |
| 2 | Ben Schmidt | Beispielweg 5, Hamburg | Transporter | 80 |
| 3 | Anna Müller | Musterstraße 1, Berlin | PKW | 50 |
Vorteil: Du kannst Mietungen direkt abfragen, ohne Joins. Nachteil: Wenn sich die Adresse von Anna Müller ändert, musst du sie an mehreren Stellen anpassen – Fehlerquelle!
Faustregel
Normalisiere deine Daten zunächst bis 3NF. Wenn Performanceprobleme auftreten, kannst du gezielt denormalisieren. Wichtig: Dokumentiere jeden Schritt und überprüfe die Daten auf Konsistenz.
Häufige Fehler & Lösungen
Auch bei sorgfältiger Normalisierung schleichen sich oft typische Fehler ein. Hier zeigen wir dir, welche Probleme häufig auftreten und wie du sie erkennst und behebst.
Fehlermuster
- „Pseudoatomare“ Werte: Manche Zellen enthalten mehrere Informationen, z. B. ISO-Codes in einem String oder mehrere Produkte in einer Zelle.
- Zyklische Abhängigkeiten: Tabelle A hängt von Tabelle B ab und B wieder von A – das kann zu Problemen bei Updates und Löschungen führen.
- Übernormalisierung: Tabellen werden zu stark zerlegt, z. B. 1:1-Beziehungen unnötig in separate Tabellen ausgelagert. Das verkompliziert Abfragen ohne Vorteil für Datenintegrität.
Beispiel: Pseudoatomare Werte
Nicht normalisiert:
| bestell_id | produkte |
|---|---|
| 1 | ProduktA, ProduktB, ProduktC |
| 2 | ProduktD |
Problem: Du kannst SELECT nicht leicht filtern, z. B. nach einem einzelnen Produkt.
Lösung: Aufteilen in separate Tabelle bestellpositionen:
| bestell_id | produkt |
|---|---|
| 1 | ProduktA |
| 1 | ProduktB |
| 1 | ProduktC |
| 2 | ProduktD |
Debugging: 3NF-Verletzungen finden
Du kannst in SQL gezielt prüfen, ob transitive Abhängigkeiten existieren:
SELECT DISTINCT a, b
FROM tabelle
GROUP BY a, b
HAVING COUNT(DISTINCT c) > 1;
Erklärung: Diese Abfrage hilft, Fälle zu entdecken, in denen ein Attribut von einem anderen abhängt, das wiederum von einem dritten abhängt – genau das, was 3NF verhindern soll.
Tipps für Anfänger
- Überprüfe deine Tabellen auf zusammengesetzte Werte in einer Zelle.
- Stelle sicher, dass jeder Primärschlüssel wirklich alles eindeutig identifiziert.
- Vermeide unnötige Zerlegungen – Einfachheit ist oft besser als maximale Normalisierung.
Cheat Sheet: Normalisierung im Überblick
| Normalform (NF) | Prüffrage | Lösungstechnik | Praxis-Check |
|---|---|---|---|
| 1NF | Enthält eine Zelle Mehrfachwerte? | Atomare Spalten | Keine Arrays oder Kommas in einer Zelle |
| 2NF | Hängt ein Attribut vom Teil eines zusammengesetzten Primärschlüssels ab? | Zerlege Tabelle | Nur Abhängigkeiten vom vollständigen Primärschlüssel |
| 3NF | Gibt es transitive Abhängigkeiten (X → Y → Z)? | Extrahiere Entität | Vermeide, dass ein Attribut indirekt von einem anderen abhängt |
| BCNF | Ist jede Determinante ein Kandidatenschlüssel? | Schlüssel neu definieren | Bei mehreren Kandidatenschlüsseln besonders prüfen |
- Normalisierungs-Checker in MySQL Workbench
- Python-Skripte zur Analyse von funktionalen Abhängigkeiten
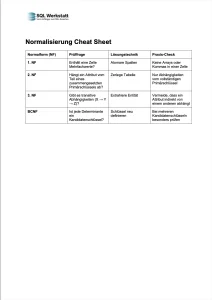
Hier kannst du das Cheat Sheet zur Normalisierung mit Prüffragen, Lösungstechnik und Praxis-Check runterladen: Normalisierung Cheat Sheet (PDF)
Beispiel: Normalisierung
Ausgangssituation: Nicht-normalisierte Tabelle
| Bestellung_ID | Kunde_Name | Artikel_Liste | Artikel_Preise | Lieferant | Lieferant_Adresse |
|---|---|---|---|---|---|
| 1 | Anna | Stift, Heft | 2€, 3€ | BüroPlus | Hauptstraße 5 |
| 2 | Max | Stift | 2€ | BüroPlus | Hauptstraße 5 |
| 3 | Lara | Heft | 3€ | SchreibwarenX | Marktstraße 12 |
Schritt 1: Erste Normalform (1NF)
Jede Zelle enthält nur einen Wert. Artikel werden auf eigene Zeilen verteilt:| Bestellung_ID | Kunde_Name | Artikel | Artikel_Preis | Lieferant | Lieferant_Adresse |
|---|---|---|---|---|---|
| 1 | Anna | Stift | 2€ | BüroPlus | Hauptstraße 5 |
| 1 | Anna | Heft | 3€ | BüroPlus | Hauptstraße 5 |
| 2 | Max | Stift | 2€ | BüroPlus | Hauptstraße 5 |
| 3 | Lara | Heft | 3€ | SchreibwarenX | Marktstraße 12 |
Schritt 2: Zweite Normalform (2NF)
Teilabhängigkeiten entfernen. Artikelinformationen hängen nur noch vom Artikel:Artikel-Tabelle
| Artikel_ID | Artikel_Name | Artikel_Preis | Lieferant |
|---|---|---|---|
| 101 | Stift | 2€ | BüroPlus |
| 102 | Heft | 3€ | BüroPlus |
| 103 | Heft | 3€ | SchreibwarenX |
Bestellpositionen-Tabelle
| Bestellung_ID | Artikel_ID | Menge |
|---|---|---|
| 1 | 101 | 1 |
| 1 | 102 | 1 |
| 2 | 101 | 1 |
| 3 | 103 | 1 |
Bestellungen-Tabelle
| Bestellung_ID | Kunde_Name |
|---|---|
| 1 | Anna |
| 2 | Max |
| 3 | Lara |
Schritt 3: Dritte Normalform (3NF)
Transitive Abhängigkeiten entfernen. Lieferant_Adresse hängt nur von Lieferant, daher eigene Tabelle:Lieferanten-Tabelle
| Lieferant | Lieferant_Adresse |
|---|---|
| BüroPlus | Hauptstraße 5 |
| SchreibwarenX | Marktstraße 12 |
Artikel-Tabelle (aktualisiert)
| Artikel_ID | Artikel_Name | Artikel_Preis | Lieferant |
|---|---|---|---|
| 101 | Stift | 2€ | BüroPlus |
| 102 | Heft | 3€ | BüroPlus |
| 103 | Heft | 3€ | SchreibwarenX |

Dieses Beispiel zur Normalisierung, welches von der Ausgangsbasis bis zur 3. NF alle Schritte zeigt, kannst du hier runterladen: Normalisierung Beispiel (PDF)
Fazit
Die Normalisierung von Datenbanken ist kein Selbstzweck, sondern ein bewährtes Hilfsmittel, um Ordnung in komplexe Datenstrukturen zu bringen. Indem du Schritt für Schritt von der 1. über die 2. bis hin zur 3. Normalform gehst, stellst du sicher, dass deine Daten konsistent, widerspruchsfrei und flexibel nutzbar bleiben. Besonders in der Ausbildung und im Studium ist es wichtig, diesen Prozess nicht nur theoretisch zu kennen, sondern auch praktisch nachvollziehen zu können – so wird deutlich, warum redundante Daten langfristig zu Problemen führen.
Gleichzeitig gilt: Normalisierung ist ein Werkzeug, kein Dogma. Für die meisten Anwendungsfälle reicht es völlig aus, Tabellen bis zur 3. Normalform zu bringen. Darüber hinaus gehende Normalformen oder auch Denormalisierung können in speziellen Szenarien sinnvoll sein, etwa wenn es um Performance im Data Warehousing geht. Entscheidend ist, dass du die Grundlagen verstehst und bewusst abwägen kannst, welche Form der Modellierung für dein Projekt am besten geeignet ist.

NULL-Werte in SQL: Was sie wirklich bedeuten und wie du damit umgehst
Auf einer Party fragst du jemanden nach seinem Geburtsdatum –...
Artikel lesen
Was sind SQL-Abfragen?
Datenbanken enthalten oft Millionen von Datensätzen, von Kundendaten über Produktinformationen...
Artikel lesen
Indexes verstehen: Warum manche Queries ewig dauern und andere nicht
Hattest du jemals eine SQL-Query, die mal in Millisekunden und...
Artikel lesen
Warum deine SQL-Abfrage keine Ergebnisse liefert – 5 häufige Ursachen
Du hast deine SQL-Abfrage geschrieben, sie läuft ohne Fehlermeldung durch...
Artikel lesen